
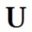
Kubernetes is very famous to host stateless applications. With the growth in popularity of containers, companies began to provide ways to manage both stateless and stateful containers in Kubernetes. Stateful applications stores information locally or on the remote storage. Stateful apps use the same servers/pods each time they process a request from a user. Stateful apps track things like window location, setting preferences, and recent activity. You can think of stateful transactions as an ongoing periodic conversation with the same person. If your app requires more memory of what happens from one session to the next, then stateful might be the way to go.
Example of stateful applications:
- All RDS databases (MySQL, SQL)
- Elastic search, Kafka , Mongo DB, Redis etc…
- Any applicaiton that stores data
Stateless applications do not keep a record of each interaction/state. Each request is handled completely as a new request. There is no stored knowledge of or reference to past transactions. Each transaction is made as if from scratch for the first time. Think of stateless transactions as a vending machine: a single request and a response. Stateless applications are simple, reliable, fast, and efficient. But this approach has its drawbacks
Example of Stateless applications:
- Any application that doesn’t stores data
- web applications (node js, apache , nginx, Tomcat etc..)

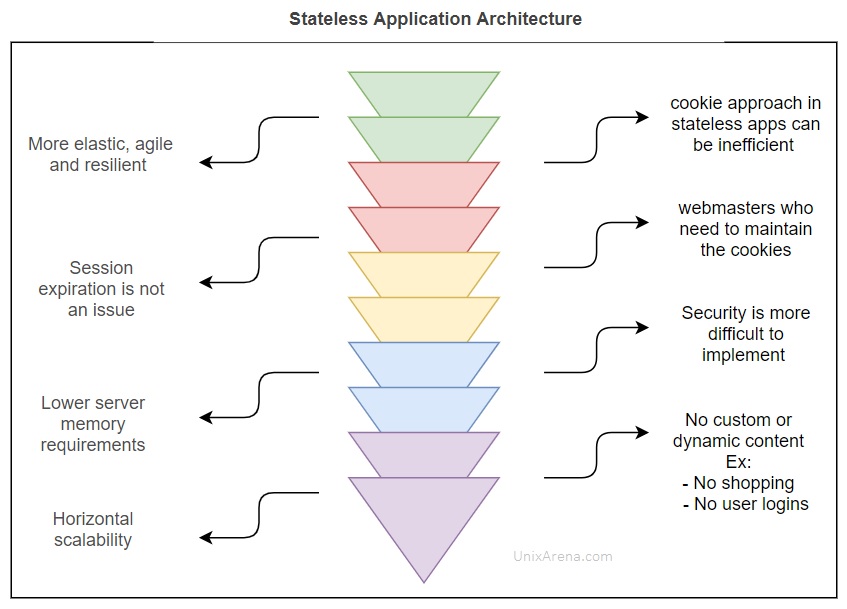
How Stateless applications are deployed in Kubernetes ?
Stateless applications are deployed using the “deployment” controller in Kubernetes. A deployment provides declarative updates for Pods and ReplicaSets. The “Deployment” component allows replicating the pods. Pods are interchangeable in the deployment. In a stateless application like an apache web server, the client does not care which pod receives a response to the request. The connection reaches the service, and it routes it to any backend pod that deployment manages.

Jobs -> Kubernetes Job controller is responsible to perform a specific job or schedule something similar to a cron job. A simple case is to create one Job object in order to reliably run one Pod to completion. Jobs are not intended to host any application.
How Stateful applications are deployed in Kubernetes ?
In the container world, most of the time you don’t care how your pods are scheduled, but sometimes you care that pods are deployed in order, that they have a persistent storage volume, or that they have a unique, stable network identifier across restarts and reschedules. In such cases, the StatefulSets controller can help you to accomplish your objective. Stateful applications are deployed using the “statefulsets” controller in Kubernetes. StatefulSet keeps a unique identity for each Pod it manages. It uses the same identity whenever it needs to reschedule those Pods. In simple words StatefulSets = Deployment + unique network identifiers.
StatefulSets use cases;
StatefulSets are valuable for applications that require one or more of the following.
- Stable, unique network identifiers.
- Stable, persistent storage.
- Ordered, graceful deployment and scaling.
- Ordered, automated rolling updates.
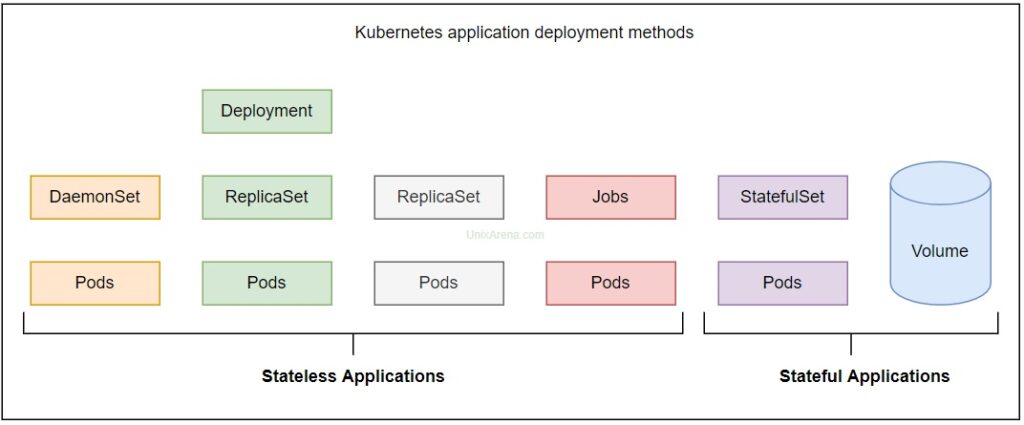
The following picture explains how scale down and scale up will happen in StatefulSets controller. You can see that every object has its sticky identity number unlike deployment controller which primarily works with randam numbers.

Hope this article has given little glimpse about stateful and stateless application deployments in Kuberenetes. Both the method has its own advantages and disadvantages. Most of the cases, application requirement decides the type of application. You can’t ignore the robust scaliablity of stateless application, at the same time stateless application always depends on stateful applications (Ex: DB) to store the data. At any given point of time, both type of applications will be exists in your environment.